Anatomy of the Zotero Library to RSS Feed Pipe
Last week I posted about a Yahoo Pipes construct that turns a Zotero website library into an RSS feed. As Dan Cohen noted in a twitter response to the posting, the Zotero team is planning to add an RSS capability in a future release of the website, so this pipe will ultimately be usurped by that capability, but in the meantime it is a handy tool. It was my first full-scale foray into creating a Yahoo Pipes construct from scratch, so I thought it would be useful to document how it works (in case I need to do something similar again). You might find this useful, too; especially the part about how to put a pubDate element into the RSS feed.
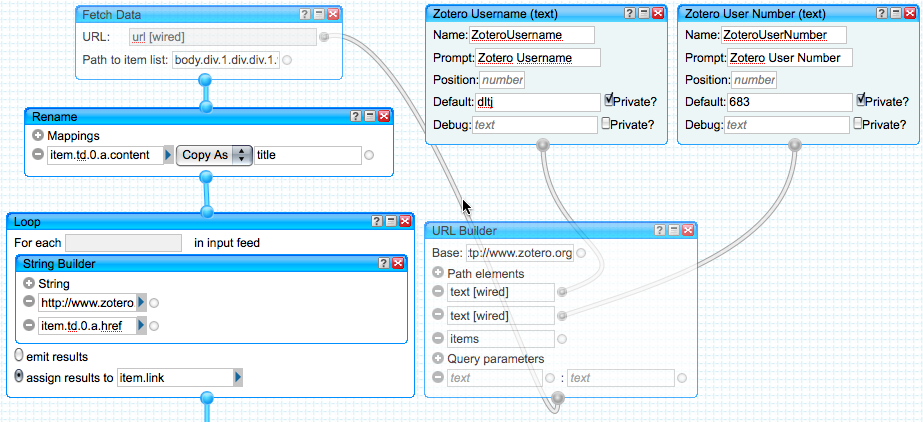
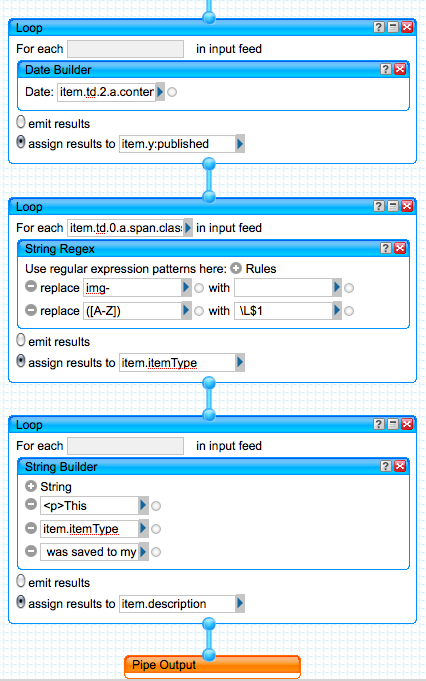
[caption id="attachment_788" align="alignnone" width="927" caption="Graphic representation of the Yahoo! Pipes construct to turn a Zotero library web page into an RSS feed."]
 |
|
 |
A couple of things to note:
|
[/caption]
The process starts with the two Private Text Input modules at the top right — one each for the Zotero Username and the Zotero User Number. The defaults are set to my values, and they are marked private — meaning that if someone clones this pipe, these values are not carried along.
Directly below is a URL Builder module. The base URL is http://www.zotero.org, and there are three path elements: the first is a connection from the Zotero Username Private Text Input, the second is a connection from the Zotero User Number Private Text Input, and the third is the literal "items". This builds a URL that looks like http://www.zotero.org/dltj/683/items and that corresponds to the Zotero user's library items page.
Starting at the upper left of the diagram, the output of the URL Builder is connected to the URL field of a Fetch Data module. The "Path to Item List" parameter is set to body.div.1.div.div.1.table.tbody.tr and that is a pointer to the portion of the XHTML document that contains the library items. Because the Zotero website is outputting XML (as XHTML), we can use the Fetch Data module and parse the page as if it was an XML document. The Path to Item List is an XPATH-like structure that points into the document structure (see note above). The result of this module is a list of items — the table rows in this case — that are processed by the remaining modules.
The next module down is a Rename module, where the value of the XPATH-like path item.td.0.a.content is copied to the item title element. The XPATH, from the root of the "Path to Item List" in the module above, is td/a; note here the added item at the front and the content at the end. Specifying the zeroth td element isn't needed, but it brings symmetry with subsequent modules. content corresponds to the text node under the a element when viewing this as an XML document.
What follows is a series of Loop modules that act on different parts of the items in the list. The first builds the link element of the item using the String Builder module. The href in the XML is a relative path, so the String Builder adds the literal "http://www.zotero.org" to the value found in item.td.0.a.href (the href attribute of the anchor element of the first td element). The resulting string is assigned to the link element of each item in the list.
The second Loop module encapsulates a Date Builder module, and this is the inspiration for writing this post. It took a very long time to figure out how to get the pubDate element into each item of the resulting RSS feed. As it turns out, one cannot simple assign the pubDate element like we did the title element above. Instead, one sets the timestamp to the y:published element and Yahoo Pipes takes it from there. And it isn't enough to assign a text string to that element; it has to be a Date type, constructed using the Date Builder module. The Date Builder module is very flexible in what it accepts, and it creates a canonical timestamp form that can be used by other modules. In this case, the Date Builder module takes as a source input the string value found at item.td.2.a.content. Believe me -- it took a long time to figure this out, and it was only done by piecing together various suggestions and examples; there doesn't seem to be any clear documentation about this.
The third and fourth Loop modules go together. The third takes the value found in This journal article was saved to my Zotero library.item.td.0.a.span.class and applies a String Regex module to it. The value of that class attribute contains the type of item in the Zotero library, and it takes the form of "img-book" or "img-journalArticle" or "img-conferencePaper". There are two regular expressions defined: the first removes the "img-" prefix from each value and the second replaces all instances of an upper case letter with a space plus the lower case version of the letter. The latter rule turns "journalArticle" into "journal article" (note that there is a space in this field prior to the \L part). The result is assigned to the item.itemType element. This is used in the final Loop module to build a item.description element to create the string:
.
That's all there is to it. Yahoo Pipes applies all of these modules to each of the items in the list retrieved from the Zotero library page and generates the corresponding RSS feed.