Working With the Web Architecture
As you may have noticed, the web has evolved a set of common principles that are a mix of ratified standards and ad hoc practices. The notion of a Web Architecture was codified in a W3C technical report called "Architecture of the World Wide Web" http://www.w3.org/TR/2004/REC-webarch-20041215/ or simply 'Web Architecture.' Those projects and protocols that align with the 'Web Architecture' are more likely to be picked up and used than those that do not. As a result, the OAI Object Reuse and Exchange (ORE) project seeks to provide an infrastructure for web-based information systems that exploit and enhance the Web Architecture, and therefore overlay cleanly on the existing web.
Given that we want to align closely with this 'Web Architecture' how far does the Web Architecture report go to define what is needed to make an ORE environment happen? The answer lies in the definition of three terms and the interaction of these three concepts.
- Resource: "A network data object or service that can be identified by a URI.... Resources may be available in multiple representations (e.g. multiple languages, data formats, size, and resolutions) or vary in other ways."
"Hypertext Transfer Protocol -- HTTP/1.1" RFC 2616. Available from http://www.ietf.org/rfc/rfc2616 Accessed Feb 15 2007. - Uniform Resource Identifier (URI): "A compact string of characters for identifying an abstract or physical resource."
"Uniform Resource Identifiers (URI): Generic Syntax" RFC 2396. Available from http://www.rfc-editor.org/rfc/rfc2396.txt Accessed Feb 15 2007. - Representation: "An entity included with a response that is subject to content negotiation.... There may exist multiple representations associated with a particular response status."
"Hypertext Transfer Protocol -- HTTP/1.1" RFC 2616. Available from http://www.ietf.org/rfc/rfc2616 Accessed Feb 15 2007.
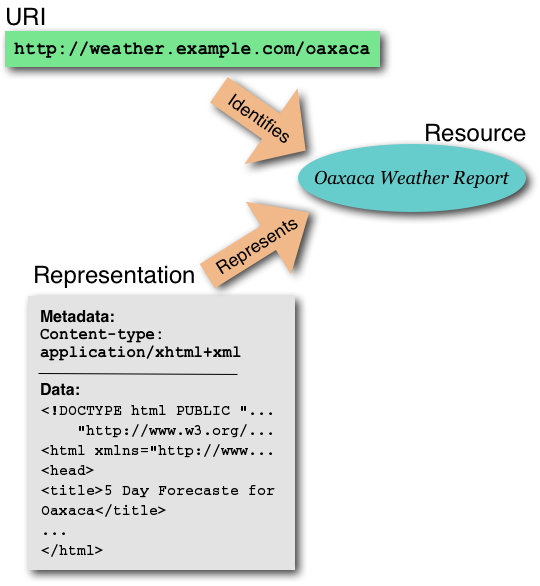
This is perhaps best explained by this graphic from the "Architecture of the World Wide Web" document. All three terms are included: a URI identifies a resource which is in turn expressed as one representation. The key part of how the web works, though, lies in the definition of "representation" — that there may exist multiple representations for a single URI. Believe it or not, you already know this. The representation of the resource identified by the URI 'cnn.com' at noon today is different from the one that existed at noon yesterday. You might say, "well so what...it is a dynamic website," and I would agree — what is important here is that the web architecture does not give you a way to identify with a URI that representation of the cnn.com resource at noon yesterday. Put another way, in the words of the Web Architecture technical report, "Agents [web browsers and the like] may use a URI to access the referenced resource; this is called dereferencing the URI."
The Web Architecture technical report lists four factors that determine which representation(s) are retrieved as a result of a service request:
- Whether the URI owner makes available any representations at all;
- Whether the agent making the request has access privileges for those representations...;
- If the URI owner has provided more than one representation (in different formats such as HTML, PNG, or RDF; in different languages such as English and Spanish; or transformed dynamically according to the hardware or software capabilities of the recipient), the resulting representation may depend on negotiation between the user agent and server.
- The time of the request; the world changes over time, so representations of resources are also likely to change over time.
When a URI is accessed by a browser, one goes through a content negotiation to get a representation. Representations may vary by device or time or IP address or authorization or any number of factors. In a graph or type-based thinking, a resource is a first class object: it is linkable — one can cite a resource. Representations, on the other hand, are second class objects: identified only in the context of a resource. A representation is not linkable, there may be many representations per resource, and a representation only comes about as a result of an action.
Observations
This notion of the 'Web Architecture' is clearly dominant now, so what does the Web Architecture — resources, URIs, and representations — mean in the context of the OAI Object Reuse and Exchange work? One would be well advised to use its existing capabilities where they are appropriate and build specialized extensions that sit on top in such a way as to not contradict its fundamental aspects. This means cleanly layering new capabilities that meet the needs of our problem space. In a subsequent posting, I'll outline the need for some ORE-specific extensions to the Web Architecture.