The Intersection of the Web Architecture with Scholarly Communication
Two previous posts on dltj.org have described the OAI Object Reuse and Exchange (ORE) project and the theory behind what has become known as the 'Web Architecture'. These two areas meet up now in this post which describes the issues surrounding the raw Web Architecture as applied to a web of scholarly communication and a basic outline of what the ORE project hopes to accomplish.
Problems With the Web Architecture
The concepts behind the Web Architecture are clearly successful. I believe it is safe to assert that the genius behind the creation of Tim Berners-Lee and his colleagues is the simplicity with which the vast web of world wide connections has sprung into existence with relatively little coordination. That said, some of the fundamental concepts behind the Web Architecture do not fit well with the web of interactions known as "scholarly communication."
The first issue is aggregation. The Web Architecture does not provide a way to describe a finite set of Resources and relationships as a citable complex digital object resource structure. As scholarly communication becomes more than just papers — it can also now include data sets, supplementary graphics, primary source material as well as references to previously publish objects — this concept of aggregation becomes important.
Second, the relationships between Resources are usually untyped and link type ontologies are not well defined. (Capital-R "Resources" carries the meaning of this term as defined by the standards related to the Web Architecture; see the previous posting for a definition and examples.) Is this link within the text of a document a citation? A data set? An explanatory graphic? In general, it is not good practice to try to guess the relationship based on the contents of the URI itself. In fact, the Web Architecture technical report suggests "agents making use of URIs SHOULD NOT attempt to infer properties of the referenced resource."
The Problems From a Scholarly Communication Perspective
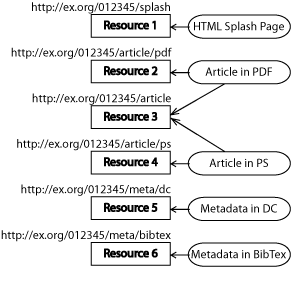
Take, for example, a paper in an example repository as described by this graphic. The article, identified by the number "012345" has six Resources with five Representations: an HTML splash page generated by the repository software (Resource #1), the article in PDF format (Resource #2), the article in Postscript format (Resource #4), metadata in Dublin Core XML (Resource #5), metadata in BibTex format (Resource #6), and the article in a format decided by agent/server content negotiation (#3).
Although it may be possible to infer that all six Resources are related by comparing the leading fragment of the URIs, the Web Architecture principle of URI opacity dictates that we shouldn't make those assumptions. Furthermore, even if we could determine that they are related based on examining the URIs, we do not have a consistent vocabulary to define that relationship. Is "...meta/bibtex" the citation data for this article or is it the list of citations used in the article?
Modeling Complex Objects
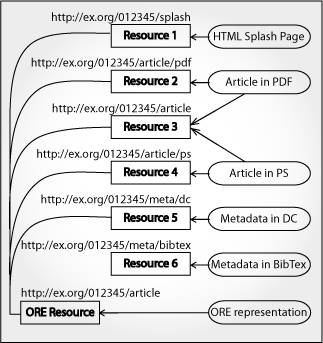
Because the Web Architecture does not allow for the definition of a boundary for a compound digital object, the ORE project proposes the definition of a Resource — called the ORE Model, for lack of a better name at the moment — that formally expresses a bounded aggregation of resources and relationships that corresponds to a compound digital object. Put another way, an instantiation of the ORE Model is a map of other resources that expresses the boundaries of the compound digital object. A URI identifies the compound digital object — the ORE Resource — and a service request on that URI returns a Representation that is some serialization of the ORE Model.
The preliminary version of the model describes two types of relationships: intra-aggregation relationships (inside the boundaries of the compound digital object) and inter-aggregation relationships (to Resources outside the boundary of this compound digital object). The intra-aggregation relationships come in two forms: hasPart (where one Resource contains other Resources, such as books contain chapters or journal issues contain articles) and hasView (where the target Resource is a semantically equivalent presentation format, such as Word and PDF versions of an article). The inter-aggregation relationship has only one verb, "hasRelationshipTo," which simply means the target of the relationship is considered outside the boundaries of the complex digital object. From a base verb of "hasRelationshipTo" other communities can apply specialized relationships.
The result describes a connected sub-graph with a finite set of resources and relationships among those resources to form a compound digital object plus relationships to resources that are external to the aggregation. With that in place, we can consider services that can be applied to portions of the graph.
ORE Services
One half of the work of the ORE project is to define a model for compound digital objects in a Web Architecture environment. The other half of the work is to define the meaning of services that exchange instances of the model to form the basis of a Web Architecture-aware scholarly communication environment.
Conceived based on the experiences with the OAI Protocol for Metadata Harvesting (PMH), there are three archetypes of services.
- Harvest: a request for a batch of instances that correspond to the ORE model from a set of ORE Resources.
- Obtain: A request for an instance that corresponds to the ORE Model from a specific ORE Resource.
- Register: A request to add new nodes or relationships to an ORE aggregation.
Service requests against the ORE Resource URI are the access points for these activities.
For more information...
This is a basic introduction to the work of the technical committee so far. For a more in-depth view into the outcomes of the first face-to-face meeting, including expanded definitions and examples of what was outlined here, see the Report of the January 2007 ORE-TC Meeting. In addition, there is a interview with Herbert van de Sompel recorded at the CNI 2006 Fall Task Force to go along with a project briefing presented at that meeting. (Keep in mind that these were recorded and presented before the first technical committee meeting, so some of the concepts of the implementation have changed.) Pete Johnson, a member of the ORE technical committee, posted his thoughts on the topic on his blog: Prospecting for ORE, More ORE, and More ruminations on compoundness and complexity (and metadata). The presentation slides from Carl Lagoze's talk at Open Repositories 2007 are also available, of which Chris Wilper and Jim Downing posed summaries and reactions. Also keep an eye on the OAI-ORE tag on Technorati for more updates and reactions.
The text was modified to remove a link to http://technorati.com/tag/OAI-ORE on January 19th, 2011.
The text was modified to update a link from http://www.cni.org/tfms/2006b.fall/abstracts/PB-oai-sompel.html to http://www.cni.org/pbs/cni2006fallpb/the-oai-object-re-use-exchange-ore-initiative/ on August 22nd, 2013.