It's coming up on four months this week since I left Twitter, and I started wondering about the impact of that.
On the whole, I'm still quite fine with the decision.
(If you need an itemized list of how Twitter is falling short of its history and its idealized self …
My relationship with Twitter crossed a new line yesterday. As I posted on Mastodon (one, two):
Have just deleted the Twitter app on mobile. Felt the need to ramp down stress this week, and the current owner’s meltdown is unnecessary drama. There are still a few people there that …
Well, this newsletter was off the air longer than I anticipated.
A lot has happened since issue 90 in late March: cryptocurrency value falling, Twitter spiraling (maybe a death-spiral...can't be too sure), and (in the U.S.) a whopper of a mid-term election season.
All is well here in …
DALL*E prompt: photorealistic waves of twitter logos and mastodon logos crashing onto a sandy beach
Much has been made about the differences between Twitter and Mastodon: the challenge of finding a home for your account (and the corresponding differences between your “local” timeline and your “global” timeline), the intentional …
So I had an idea for a Twitter bot I would like to see. Occasionally I'll be listening to a story on NPR and I'll want to know more about it. Sometimes the host will say something like: "come to npr.org for more information and click on..." Other times …
Earlier this month I found myself apologizing for some errant tweets that ended up in my Twitter stream ((The problem turned out to be a forgotten automatic posting of blog posts into Delicious. When I was cleaning up links in posts using, these post changes were being added as new …
Over the weekend I got the bright idea of asking OmniGroup to ask an iPhone voice recognition application (like Dragon Dictation) to add a link to the OmniFocus iPhone application. That way I could simply dictate new inbox items on the iPhone rather than laboriously typing them with the on-screen …
Emily Clasper of the Suffolk County Library posted about some work she had done to embed status messages in the catalog using Twitter. This sounded like a really great idea because it is an out-of-band (e.g. something that doesn't rely on OhioLINK infrastructure for reporting downtimes) way to get …
The following may not be news to those who regularly hang out in Twitter-land, but the extent of the problem recently became clear to me: there is a bunch of spam in Twitter. More specifically, there appear to be robots that do nothing but scan the web for keywords and …
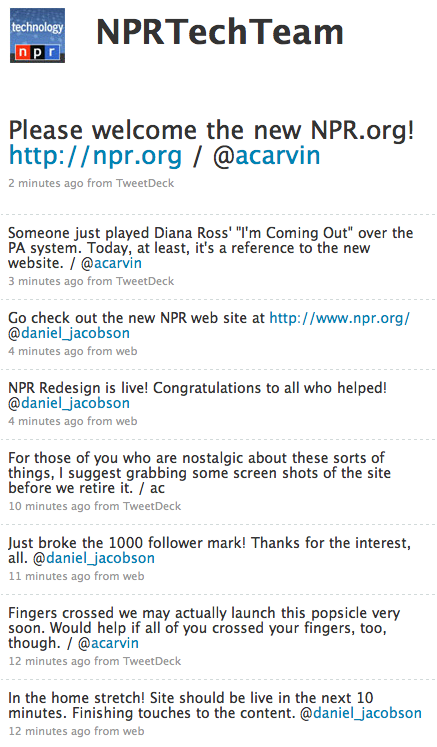
Image capture of NPR Tech Team Twitter account.
All day today, the staff at NPR's Digital Media team have been preparing to launch a new version of their website, and we've been able to follow along via tweets on the NPRTechTeam Twitter account. It looks like it was a marathon …
As a youth I remember intently studying the troubles of others -- what they did when they got into trouble and how they got out of it. If the saying "You Learn From Your Mistakes" was so true, I wanted to be able to learn from the mistakes of others. I …
As libraries feel the need to join the social media landscape to meet a segment of their user population already there, it is useful to step back and get acclimated. There is a pace of information flow that is unlike anything else in the physical world, and a minor incident …
The American Library Association annual conference is getting more social each year, and as a long-time member of ALA and often a critic of the, well, un-togetherness of ALA's electronic capabilities, it is nice to see the trend continuing this year. Take, for instance, the Blogger's Room. Initially just a …
It was only a few months ago that I was teasing Dan Chudnov for joining Twitter. Now I've gone and done it myself. I don't expect to be using it much, but after observing the "Falls Church, VA" incident yesterday, I thought it would be an useful tool to have …