Traditional Development/Integration/Staging/Production Practice for Software Development
Recently, I was asked to outline a plan for a structured process for software development that maximizes productivity and reduces bugs that reach the user. This was originally an internal OhioLINK document, but the process described is pretty traditional and others might find a use for this as well. You are welcome to use this; please honor the Creative Commons licensing terms and contact me in advance if you need something different.
 This article is translated to Serbo-Croatian language by Anja Skrba from Webhostinggeeks.com. This article is translated to Slovak language by Juraj Rehorovsky from Everycloud. This article is translated to Belarusian by Vicky Rotarova. This article is translated into Romanian by Milos Onichanu.
This article is translated to Serbo-Croatian language by Anja Skrba from Webhostinggeeks.com. This article is translated to Slovak language by Juraj Rehorovsky from Everycloud. This article is translated to Belarusian by Vicky Rotarova. This article is translated into Romanian by Milos Onichanu.
Creating Applications in Four Tiers
Let's start first with a description of the four tiers for software development.
- Development
- Optional. This is the working environment for individual developers or small teams. Working in isolation with the rest of the tiers, the developer(s) can try radical changes to the code without adversely affecting the rest of the development team.
- Integration
- A common environment where all developers commit code changes. The goal of this environment is to combine and validate the work of the entire project team so it can be tested before being promoted to the Staging Environment. It is possible for Development and Integration to be the same environment (as in the case where the developer does not use a local copy of the source code).
- Staging
- The staging tier is a environment that is as identical to the production environment as possible. The purpose of the Staging environment is to simulate as much of the Production environment as possible. The Staging environment can also double as a Demonstration/Training environment.
- Production
- The production tier might include a single machine or a huge cluster comprising many machines.
These tiers speak of "environments" rather than "machines" or "servers." It is certainly possible for multiple Development environments and the Integration environment to be on the same physical machine, or the Integration and Staging environments to be on the same machine. If at all possible, the Production environment should be by itself and not shared with any of the other environments.
Resources at Each Tier
Staging
- Identical software configuration as the production machine and a complete, independent copy of the production database so it is a true basis for QA testing. If you are using a Storage Area Network (SAN) or Network Attached Storage (NAS), you may be able to use the "snapshot" capabilities of the storage device to simulate a copy of the production database without requiring an entire duplicate copy of the data (and corresponding hardware).
- Comparable hardware configuration to the production system so an accurate forecast of capacity by performance testing against it and then multiplying its performance by the number of machines that will be deployed in production.
Integration
- Limited subset of data that is useful for testing "boundary conditions" in the application. It may be wise to refresh this subset of data frequently to remove the artifacts of software development and testing on the Integration environment.
Development
- The same limited subset of data as the Integration environment.
Moving Between Tiers
This graphic shows the nature of the work performed in each environment, the responsibilities of actors in each environment, and relative rate of software builds and deployments.
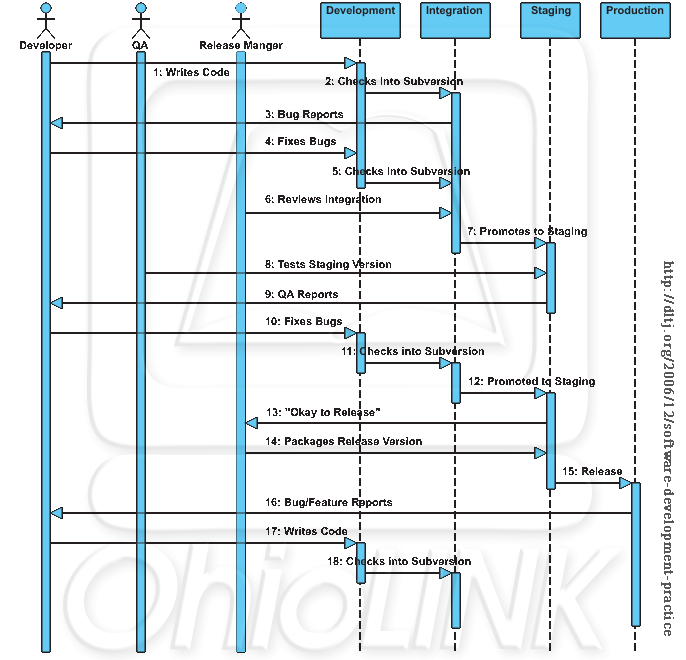
In narrative form, the software developer writes code in his or her development environment (1) and checks it into the Subversion source code repository (2). As other developers report bugs (3) more changes are made (5) and checked in (6). Remember that the Development and Integration environments can be the same actual environment, so these two boxes can be collapsed; it is important to note, though, that in such a case changes are still being checked into Subversion.
When the developers are happy with the behavior of the Integration environment (6), the Release Master creates a copy or "tag" of the code in Subversion and updates the Staging environment to this tag (7). At this point the quality assurance (QA) testers start their review (8). QA testers can be both internal staff and external reviewers; the Staging area also doubles as a training environment when the Production release is ready. QA reports go back to the developer (9) who fixes them (10) and checks the changes into Subversion (11). After all of the bugs are fixed, the release manager promotes a new version to staging (12).
This process continues until the QA team declares the staging version is "okay to release" (13). The release manager packages up the release version from Subversion (14) and deploys it on the production servers (15). As time goes on, bug reports and feature requests are made (16) for which the developer writes code (17) and checks in the changes to the source code repository (18). (17) and (18) are functionally equivalent to ''(1)'' and ''(2)'' above. Repeat until the end user is completely satisfied.
Important Notes
Developers only make changes to the Development and Integration environments. If a bug fix is to be made, the developer makes it in Subversion at the Integration stage. In order to maintain the integrity of the source code repository at no point does a developer make changes directly to the Staging or Production environments.
For each deployment to Production, there are multiple versions in Staging and for each deployment into Staging, there are multiple versions in Development/Integration. By design, end users are isolated from the rapid and occasionally buggy process of developing software. It is assumed that most bugs will be caught early and repeated versions at the early stages fill find bugs faster.
Only "release manager" can deploy versions to the next stage. There can be different release managers for deployment from Integration-to-Staging and Staging-to-Production; the release manager can even change from version to version. Of course, on some projects, the developer, the release manager, and QA tester can actually be the same person. The important point, though, is that there is always only one person responsible for deploying the new version.
Although the vertical boxes in the graphic imply the Integration environment is turned off at step ''(7)'', in reality the version of the software on the Integration environment never really goes away. Instead the version of software that is promoted to the Staging environment is "tagged" off of "trunk" in the source code repository and it is the tagged version that is copied to Staging. Work by the developers then continues on the "trunk". The same holds true for the promotion of the Staging version to production.
Coding Standards
To facilitate transfer of applications from the development server through the staging and into production, the code should be free of any server-dependent variables.
- If necessary, determine the hostname programatically rather than specifying it explicitly in the code or in the configuration. One can use either javax.servlet.ServletRequest.getServerName or javax.servlet.ServletRequest.getLocalName to determine this in a servlet.
- To ensure code is portable across file systems use relative pathnames in code and if necessary set the base directory in the application's configuration. This will enable applications and scripts to be moved from one directory on the development machine to another directory (possibly with a different path) on the production machine.