- These list items are microformat entries and are hidden from view.
- https://dltj.org/article/can-google-be-out-googled/
- I have been heard to remark to other librarians on occasion a comment along the lines of "Don't fear Google; Don't Chase Google; Let's Out-Google Google!" After allowing the confused stare linger for a moment or the hysterical laughter die down, I explain my thesis: we have something Google doesn't have — no, it isn't the selective care with which we select "authoritative" material (the PageRank algorithm does a pretty good job at that); and no, it isn't our warehouses of books (the Google Book Search project will pretty effectively capture that) — we have faceted metadata. And lots of it.Google is a big, full-text search engine. It has various algorithms for parsing the content of a web page to determine what pieces are more important than others, other algorithms for examining user's natural language query to guess what the user is really seeking (sound like a reference interview?) then yet more algorithms for relevance ranking that will push certain pages to the forefront. And guess what, it (and its peer search engines) do a pretty good job. But at their core they are still full-text search engines and a lot of educated guessing.Libraries, on the other hand, are awash with metadata. And, based on our obsession with it, we do a pretty good job. At OhioLINK, I've been privy to many a meeting where the merits of one vendor's metadata structure and quality were pitted against another, always in pursuit of the best possible metadata surrogate for our users.Who is Our Real Competition? Google or Amazon?To bring my out-Google Google thesis into sharp relief, I offer: with respect to search engines, who is a library's biggest competitor — Google or Amazon? Okay, let me ask it another way. Say you have a four-year-old who adores Disney's The Lion King (not a big stretch for my imagination -- how about you?) and she wants to have all sorts of related artifacts for her birthday party. You'd like to bake a cake or cupcakes or something like that for her. Where would you start your search? Google or Amazon?If you started from Google with a search for "Lion King Cupcakes":<img id="image95" src="/wp-content/uploads/2006/07/Google-lion_king_cupcakes.png" alt="Google Search for "Lion King Cupcakes"" /></p>Google Search Results for "Lion King Cupcakes". Note: to save space in the screen-shot, the Google-supplied advertisements and irrelevant portions of the page have been removed.Ironically (for this example) your first two hits are into Amazon pages. The next two hits are to a party store -- also a likely source of useful stuff, but you'd actually have to visit those pages to be sure. (Google's algoriths are just guessing what is on the party store pages, after all, right?) The last three hits are likely not relevant at all...a Blogspot page "posted by Cupcake", an entry into the IMDB for one of the voice actors ("cupcake" shows up in the title of another one of the actor's films), and an-odd-and-likely-irrelevant page from MySpace with the title "www.myspace.com/killsxthrills". After looking through these pages, you'd then have to do another search for "Lion King Cake" and wade through those search results as well.If you started from Amazon with a search for "Lion King" (more general than the Google search, and you'll see why that is better in a moment) you'd get the expected results of soundtracks, movies, etc. in the main search result area:<img id="image96" src="/wp-content/uploads/2006/07/Amazon-lion_king_1.png" alt="Amazon Search for "Lion King"" /></p>Amazon search for "Lion King"But along the left side is a breakdown by, in Amazon's case, product type. Look at the green-highlighted one -- "Gourmet Food" ... that sounds promising:<img id="image97" src="/wp-content/uploads/2006/07/Amazon-lion_king_2.png" alt="Amazon Search for "Lion King" Refined" /></p>Amazon search results for "Lion King", refined to "Gourmet Food".Ah! Here we go: one that I know I can throw out because I'm not interested in fruit snacks and three — two decorating kits and one pre-made party favor cookies (no baking on my part!) — that are clearly relevant. And just in case the were to be a flood of foodstuffs related to The Lion King, the faceted breakdown continues on the left side with the "Narrow by Category", "Narrow by Cuisine", "Narrow by Brand", and "Narrow by Price" options.That's the power of metadata in a search context. As libraries, we pay a lot of money for that metadata but don't make nearly as much use of it as we could in our search and browse interfaces.Is Out-Googling Possible? A Brief History of the Networked Information WorldWith me so far? So faceted browse/search with our existing rich metadata is s good thing. But can we really take on the Google Giant? Even the absence of insider information or a business plan to take on Google, you have have to consider an emphatic "yes!" as the answer. Here's why.Remember Gopher? That was going to revolutionize the world of information retrieval, and "Veronica" (the very easy rodent-oriented net-wide index of computerized archives) was right there helping us ferret out (sorry for the third rodent reference...) information from the thousands of Gopher servers around the world. In case the University of Oklahoma libraries decides that Veronica information on their website is no longer relevant, you can pull up this page out of the Internet Archive.But then this web thing came a long, and we dropped Gopher/Veronica (and WAIS, for that matter) quicker than a chipmunk being chased by a fire-breathing dragon (okay, that really stretched the rodent-to-firefox metaphor). Instead we picked up Mosaic and its follow-ons, and a new search engine — AltaVista. How many of us (that were around at the time) set our browser home pages to AltaVista? Nothing could beat it, and we all thought we were seeing the end of libraries.Then what ... remember? Yahoo came onto the scene and we all set our home pages to that. Yahoo was indexing the internet our way (with labels and hierarchies), and was searchable too. Did we think that anything could stop Yahoo?Has your home page (or at least your information discovery tool, a.k.a. "search engine") changed since the AltaVista and Yahoo days? Did you have a passing fancy with NorthernLight (blue folders!)? Have you eyed other tools?If you answered "yes" to any of those questions, can you really say that Google will remain supreme? And if not Google, then what? Could we (the library community writ large) build a knowledge discovery using as a source all of the faceted metadata we've produced in the last 30 years (MARC catalogs, Indexing/Abstracting, Citations, etc.)? And if we did it more like Amazon that Google, could we out-Google Google?Doubts To My Own VisionCan we do it? As the lead (and perhaps only) cheerleader for the Out-Google Google thesis, I'm starting to have my doubts. First came what looked like automated faceted analysis in Google. That turned out to be Google Co-op Health — a human-driven effort to add metadata to selected websites that appear in the search engine results. (By the way...why didn't we [the library profession] think of that? And now that it has been thought of why aren't we doing more with enlisting the aid of experts from their own field in categorizing their segment of the world of information?)The second, through an odd time warp, was an article in the Washington Post from last November called What Lurks in Its Soul? (I have to say "odd time warp" because although the article was published nine months ago, I only ran across it today after a Technorati search for "disruptive change AND (libraries OR library)" pulled up a blog entry from four months ago on the article.) Here is the lead paragraph:What Lurks in Its Soul?By David A. ViseSunday, November 13, 2005; Page B01The soul of the Google machine is a passion for disruptive innovation.Powered by brilliant engineers, mathematicians and technological visionaries, Google ferociously pushes the limits of everything it undertakes. The company's DNA emanates from its youthful founders, Sergey Brin and Larry Page, who operate with "a healthy disregard for the impossible," as Page likes to say. Their goal: to organize all of the world's information and make it universally accessible, whatever the consequences.So I'm not sure anymore — my faith in our ability to win a black-and-white, us-versus-them battle with Google for knowledge retrieval supremacy has been shaken. Do we cede that ground to Google? Can Google, in an Innovator's Dilemma disruptive fashion, be out-Googled? Are we, the library community, the one's to do it?Your thoughts?[Edited 20060731T0826 to fix HTML and text typos.]The text was modified to remove a link to http://www.google.com/coop/topic?cx=health_devel on November 17th, 2010.The text was modified to update a link from http://library.csun.edu/About_the_Library/asrs.html to http://library.csun.edu/About/ASRS on December 31st, 2010.The text was modified to update a link from http://www.boxesandarrows.com/view/ranganathan_for_ias to http://boxesandarrows.com/view/ranganathan_for_ias on August 22nd, 2013.
- 2006-07-30T23:30:16+00:00
- 2018-01-15T20:47:28+00:00
Can Google be Out-Googled?
I have been heard to remark to other librarians on occasion a comment along the lines of "Don't fear Google; Don't Chase Google; Let's Out-Google Google!" After allowing the confused stare linger for a moment or the hysterical laughter die down, I explain my thesis: we have something Google doesn't have — no, it isn't the selective care with which we select "authoritative" material (the PageRank algorithm does a pretty good job at that); and no, it isn't our warehouses of books (the Google Book Search project will pretty effectively capture that) — we have faceted metadata. And lots of it.
Google is a big, full-text search engine. It has various algorithms for parsing the content of a web page to determine what pieces are more important than others, other algorithms for examining user's natural language query to guess what the user is really seeking (sound like a reference interview?) then yet more algorithms for relevance ranking that will push certain pages to the forefront. And guess what, it (and its peer search engines) do a pretty good job. But at their core they are still full-text search engines and a lot of educated guessing.
Libraries, on the other hand, are awash with metadata. And, based on our obsession with it, we do a pretty good job. At OhioLINK, I've been privy to many a meeting where the merits of one vendor's metadata structure and quality were pitted against another, always in pursuit of the best possible metadata surrogate for our users.
Who is Our Real Competition? Google or Amazon?
To bring my out-Google Google thesis into sharp relief, I offer: with respect to search engines, who is a library's biggest competitor — Google or Amazon? Okay, let me ask it another way. Say you have a four-year-old who adores Disney's The Lion King (not a big stretch for my imagination -- how about you?) and she wants to have all sorts of related artifacts for her birthday party. You'd like to bake a cake or cupcakes or something like that for her. Where would you start your search? Google or Amazon?
If you started from Google with a search for "Lion King Cupcakes":
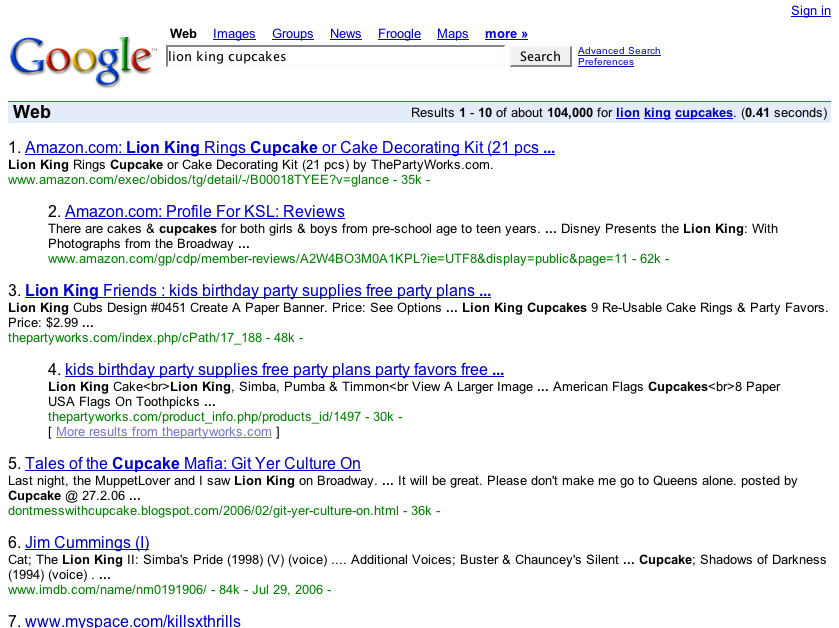
Google Search Results for "Lion King Cupcakes". Note: to save space in the screen-shot, the Google-supplied advertisements and irrelevant portions of the page have been removed.
Ironically (for this example) your first two hits are into Amazon pages. The next two hits are to a party store -- also a likely source of useful stuff, but you'd actually have to visit those pages to be sure. (Google's algoriths are just guessing what is on the party store pages, after all, right?) The last three hits are likely not relevant at all...a Blogspot page "posted by Cupcake", an entry into the IMDB for one of the voice actors ("cupcake" shows up in the title of another one of the actor's films), and an-odd-and-likely-irrelevant page from MySpace with the title "www.myspace.com/killsxthrills". After looking through these pages, you'd then have to do another search for "Lion King Cake" and wade through those search results as well.
If you started from Amazon with a search for "Lion King" (more general than the Google search, and you'll see why that is better in a moment) you'd get the expected results of soundtracks, movies, etc. in the main search result area:
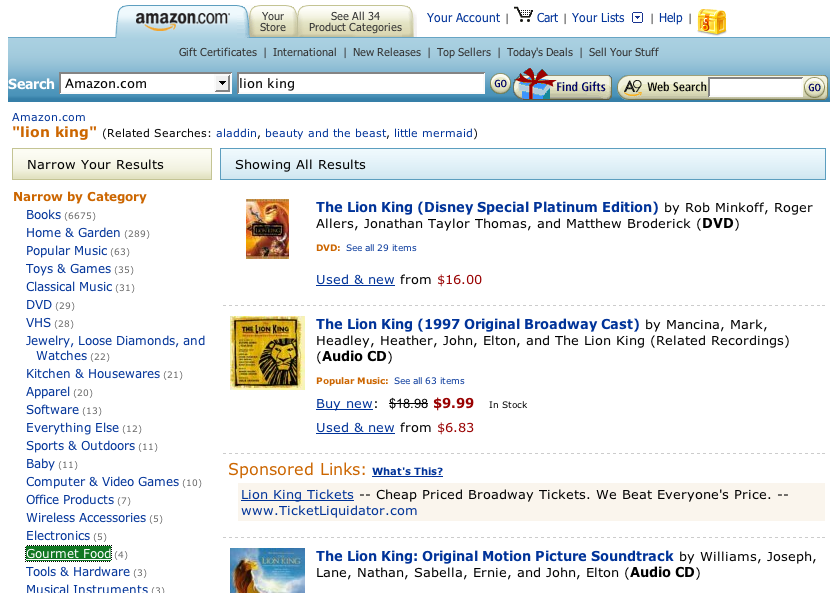
Amazon search for "Lion King"
But along the left side is a breakdown by, in Amazon's case, product type. Look at the green-highlighted one -- "Gourmet Food" ... that sounds promising:
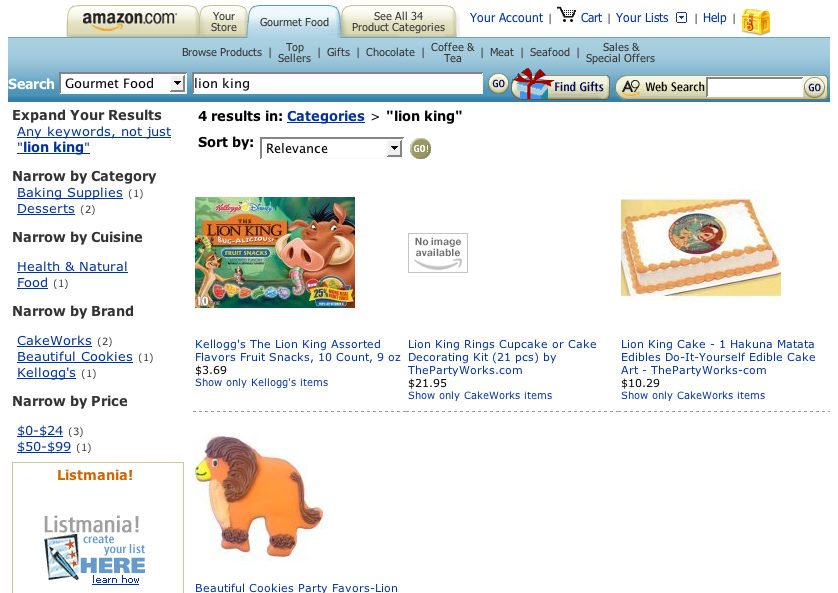
Amazon search results for "Lion King", refined to "Gourmet Food".
Ah! Here we go: one that I know I can throw out because I'm not interested in fruit snacks and three — two decorating kits and one pre-made party favor cookies (no baking on my part!) — that are clearly relevant. And just in case the were to be a flood of foodstuffs related to The Lion King, the faceted breakdown continues on the left side with the "Narrow by Category", "Narrow by Cuisine", "Narrow by Brand", and "Narrow by Price" options.
That's the power of metadata in a search context. As libraries, we pay a lot of money for that metadata but don't make nearly as much use of it as we could in our search and browse interfaces.
Is Out-Googling Possible? A Brief History of the Networked Information World
With me so far? So faceted browse/search with our existing rich metadata is s good thing. But can we really take on the Google Giant? Even the absence of insider information or a business plan to take on Google, you have have to consider an emphatic "yes!" as the answer. Here's why.
Remember Gopher? That was going to revolutionize the world of information retrieval, and "Veronica" (the very easy rodent-oriented net-wide index of computerized archives) was right there helping us ferret out (sorry for the third rodent reference...) information from the thousands of Gopher servers around the world.
But then this web thing came a long, and we dropped Gopher/Veronica (and WAIS, for that matter) quicker than a chipmunk being chased by a fire-breathing dragon (okay, that really stretched the rodent-to-firefox metaphor). Instead we picked up Mosaic and its follow-ons, and a new search engine — AltaVista. How many of us (that were around at the time) set our browser home pages to AltaVista? Nothing could beat it, and we all thought we were seeing the end of libraries.
Then what ... remember? Yahoo came onto the scene and we all set our home pages to that. Yahoo was indexing the internet our way (with labels and hierarchies), and was searchable too. Did we think that anything could stop Yahoo?
Has your home page (or at least your information discovery tool, a.k.a. "search engine") changed since the AltaVista and Yahoo days? Did you have a passing fancy with NorthernLight (blue folders!)? Have you eyed other tools?
If you answered "yes" to any of those questions, can you really say that Google will remain supreme? And if not Google, then what? Could we (the library community writ large) build a knowledge discovery using as a source all of the faceted metadata we've produced in the last 30 years (MARC catalogs, Indexing/Abstracting, Citations, etc.)? And if we did it more like Amazon that Google, could we out-Google Google?
Doubts To My Own Vision
Can we do it? As the lead (and perhaps only) cheerleader for the Out-Google Google thesis, I'm starting to have my doubts. First came what looked like automated faceted analysis in Google. That turned out to be Google Co-op Health — a human-driven effort to add metadata to selected websites that appear in the search engine results. (By the way...why didn't we [the library profession] think of that? And now that it has been thought of why aren't we doing more with enlisting the aid of experts from their own field in categorizing their segment of the world of information?)
The second, through an odd time warp, was an article in the Washington Post from last November called What Lurks in Its Soul? (I have to say "odd time warp" because although the article was published nine months ago, I only ran across it today after a Technorati search for "disruptive change AND (libraries OR library)" pulled up a blog entry from four months ago on the article.) Here is the lead paragraph:
What Lurks in Its Soul?
By David A. Vise
Sunday, November 13, 2005; Page B01
The soul of the Google machine is a passion for disruptive innovation.
Powered by brilliant engineers, mathematicians and technological visionaries, Google ferociously pushes the limits of everything it undertakes. The company's DNA emanates from its youthful founders, Sergey Brin and Larry Page, who operate with "a healthy disregard for the impossible," as Page likes to say. Their goal: to organize all of the world's information and make it universally accessible, whatever the consequences.
So I'm not sure anymore — my faith in our ability to win a black-and-white, us-versus-them battle with Google for knowledge retrieval supremacy has been shaken. Do we cede that ground to Google? Can Google, in an Innovator's Dilemma disruptive fashion, be out-Googled? Are we, the library community, the one's to do it?
Your thoughts?
[Edited 20060731T0826 to fix HTML and text typos.]
The text was modified to remove a link to http://www.google.com/coop/topic?cx=health_devel on November 17th, 2010.
The text was modified to update a link from http://library.csun.edu/About_the_Library/asrs.html to http://library.csun.edu/About/ASRS on December 31st, 2010.
The text was modified to update a link from http://www.boxesandarrows.com/view/ranganathan_for_ias to http://boxesandarrows.com/view/ranganathan_for_ias on August 22nd, 2013.
